Validation report: bridge_v1¶
Model: bridge_v1
Samples Generated: 500
Generated On: 2026-01-04 20:40
Generation Quality Metrics¶
Uniqueness |
Novelty |
SELFIES fidelity |
|---|---|---|
0.8900 |
1.0000 |
0.0083 |
Descriptor Statistics¶
Descriptor |
Average |
Minimum |
Maximum |
|---|---|---|---|
MW |
235.1938 |
133.1500 |
303.4500 |
LogP |
3.0860 |
0.4700 |
6.1200 |
SA_Score |
2.2645 |
1.0600 |
5.8900 |
QED |
0.7688 |
0.3260 |
0.9020 |
Fsp3 |
0.1675 |
0.0000 |
0.3800 |
RotatableBonds |
3.9620 |
0.0000 |
9.0000 |
RingCount |
2.3200 |
1.0000 |
4.0000 |
TPSA |
24.6952 |
0.0000 |
63.6900 |
RadicalElectrons |
0.0240 |
0.0000 |
1.0000 |
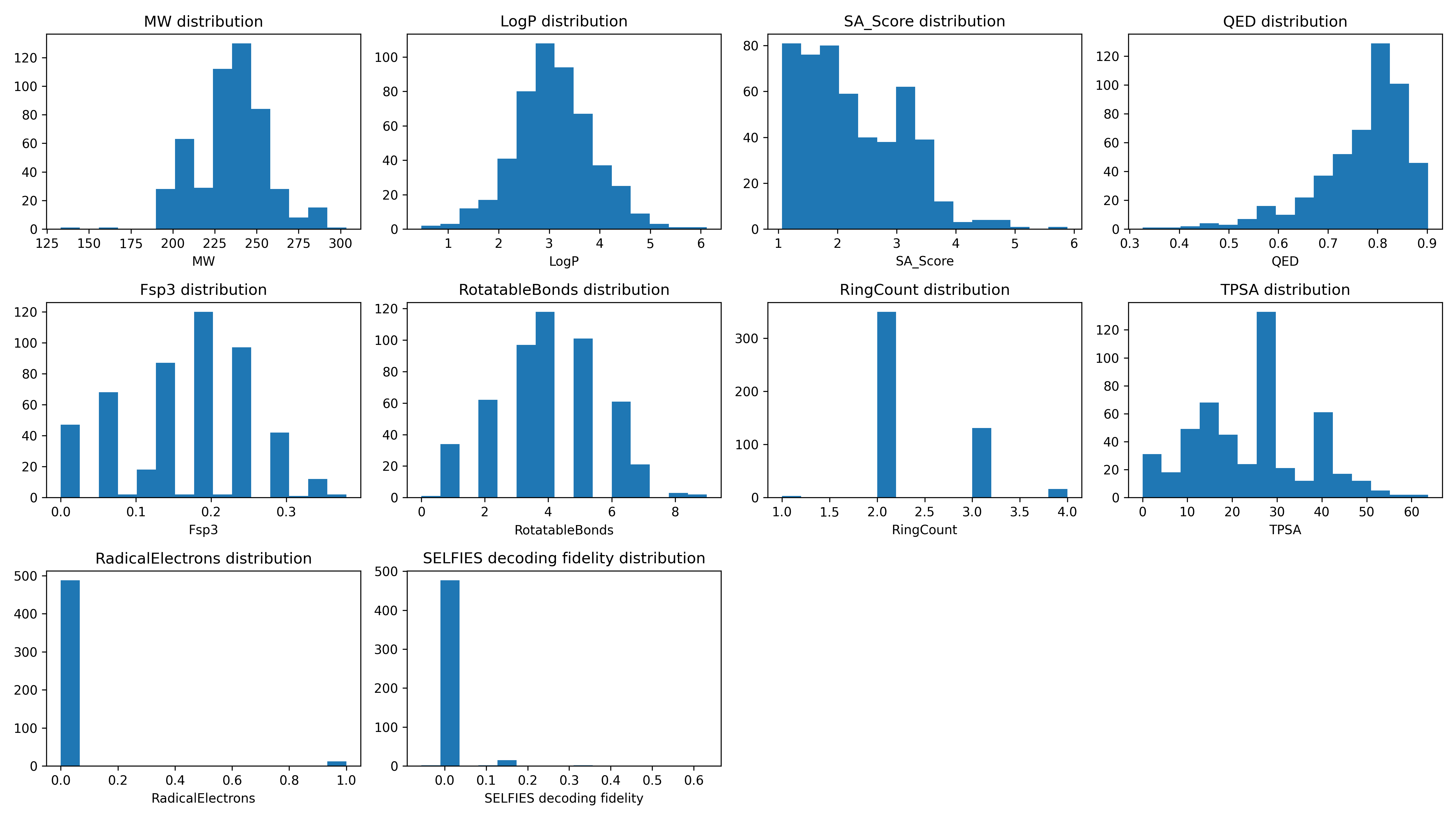
Descriptor Distributions¶
Development Notes¶
The model was trained on SELFIES sequences derived from SMILES strings, with data sourced from the QM9 and ZINC datasets. In contrast to the earlier setup in extend models, two additional control tokens—[MASK] and [BRIDGE] were introduced to explicitly model fragment bridging. As before in extend models, SMILES randomization was applied at data loading time using non-canonical RDKit SMILES to increase sequence diversity. Training was stopped once the loss reached a clear plateau, even after lowering the learning rate to 1e-5.
Bridging¶
Unlike the extend models, which learned to extend SMILES directly, this approach reformulates the task as a bridge completion problem. During dataset construction, sufficiently long SELFIES sequences are split into three parts:
an initial fragment (frag1),
a contiguous segment treated as the bridge,
and an end fragment (frag2).
and the model is trained to predict the bridge tokens after [BRIDGE], followed by [END]. At inference time, two fragments are joined together as frag1 + [MASK] + frag2 + [BRIDGE] to form the prompt.
Loss Masking¶
The training loss is computed only on the predicted bridge tokens. All target positions corresponding to [START], frag1, [MASK], frag2, and [BRIDGE] are ignored by the cross-entropy loss (set to zero as this alos the padding index).
Fragmentation constraints¶
Fragmentation is attempted only for molecules with sufficient length. For SELFIES sequences longer than 10 symbols:
frag1 length is sampled randomly,
bridge length is sampled between 1 and 10 tokens,
frag2 contains the remainder.
Shorter sequences are left unfragmented and passed through unchanged, so in principle, this model can also extend by leaving frag2 empty.
PyTorch dataset was defined as follows:
class ChempleterRandomisedBridgeDataset(Dataset):
"""
PyTorch Dataset for SELFIES molecular representations.
:param smiles_file: Path to CSV file containing SMILES strings in a "smiles" column.
:type smiles_file: str
:param stoi_file: Path to JSON file mapping SELFIES symbols to integer tokens.
:type stoi_file: str
:returns: Integer tensor representation of tokenized molecule with dtype=torch.long.
:rtype: torch.Tensor
"""
def __init__(self, smiles_file, stoi_file):
super().__init__()
smiles_dataframe = pd.read_csv(smiles_file)
self.data = smiles_dataframe["smiles"].to_list()
with open(stoi_file) as f:
self.selfies_to_integer = json.load(f)
def __len__(self):
return len(self.data)
def __getitem__(self, index):
molecule_in_smiles = self.data[index]
# try randomisation
molecule = Chem.MolFromSmiles(molecule_in_smiles)
if molecule is not None:
try:
molecule_in_selfies = sf.encoder(
Chem.MolToSmiles(molecule, canonical=False, doRandom=True)
)
except Exception as e:
molecule_in_selfies = sf.encoder(molecule_in_smiles)
logger.error(f"SELFIES encoding error for randomised SMILES: {e}")
else:
molecule_in_selfies = sf.encoder(molecule_in_smiles)
symbols = list(sf.split_selfies(molecule_in_selfies))
# try fragmentation
if len(symbols) > 10:
len_frag1 = random.randint(1, len(symbols) - 8)
len_bridge = random.randint(
1, 10
) # bridge len ranges from 1 to 10.# this would be constraint later
len_frag2 = min(len_frag1 + len_bridge, len(symbols) - 1)
frag1 = symbols[:len_frag1]
bridge = symbols[len_frag1:len_frag2]
frag2 = symbols[len_frag2:]
else:
frag1 = symbols
bridge = []
frag2 = []
symbols_molecule = (
["[START]"] + frag1 + ["[MASK]"] + frag2 + ["[BRIDGE]"] + bridge + ["[END]"]
)
integer_molecule = []
# check if all symbols exist in stoi
for symbol in symbols_molecule:
if symbol not in self.selfies_to_integer:
raise RuntimeError(
f"Molecule symbol not found in stoi. Add {symbol} in stoi with correct integer mapping."
)
else:
integer_molecule.append(self.selfies_to_integer[symbol])
return torch.tensor(integer_molecule, dtype=torch.long)